Docker知识总结
docker知识总结
容器的本质
namesapce和cgroup
容器里 1 号进程对信号处理的两个要点
在容器中,1 号进程永远不会响应 SIGKILL 和 SIGSTOP 这两个特权信号;
对于其他的信号,如果用户自己注册了 handler,1 号进程可以响应。
在停止一个容器的时候,容器 init 进程收到的 SIGTERM 信号,而容器中其他进程会收到 SIGKILL 信号
CPU

Load Average
Load Average= 可运行队列进程平均数 + 休眠队列中不可打断的进程平均数

我们只要运行 ps aux | grep “ D ” ,就可以看到容器中有多少 TASK_UNINTERRUPTIBLE 状态
在 Linux 内核中有数百处调用点,它们会把进程设置为 D 状态,主要集中在 disk I/O 的访问和信号量(Semaphore)锁的访问上,因此 D 状态的进程在 Linux 里是很常见的
内存
每个容器的 Memory Cgroup 在统计每个控制组的内存使用时包含了两部分,RSS 和 Page Cache。
RSS 是每个进程实际占用的物理内存,它包括了进程的代码段内存,进程运行时需要的堆和栈的内存,这部分内存是进程运行所必须的。
Page Cache 是进程在运行中读写磁盘文件后,作为 Cache 而继续保留在内存中的,它的目的是为了提高磁盘文件的读写性能。
当节点的内存紧张或者 Memory Cgroup 控制组的内存达到上限的时候,Linux 会对内存做回收操作,这个时候 Page Cache 的内存页面会被释放,这样空出来的内存就可以分配给新的内存申请。
判断容器真实的内存使用量,我们不能用 Memory Cgroup 里的memory.usage_in_bytes,而需要用 memory.stat 里的 rss 值。这个很像我们用 free 命令查看节点的可用内存,不能看"free"字段下的值,而要看除去 Page Cache 之后的"available"字段下的值
容器可以使用Swap空间吗?
当我们设置了"memory.swappiness=0 时,在 Memory Cgroup 中的进程,就不会再使用 Swap 空间。
我们还是可以在宿主机节点上打开 Swap 空间,在容器中就是可以用到 Swap 的,同时在其他容器对应的 Memory Cgroups 控制组里,把 memory.swappiness 这个参数设置为 0,则可满足不同应用的需求
文件系统
为什么要有容器自己的文件系统?
很重要的一点是减少相同镜像文件在同一个节点上的数据冗余,可以节省磁盘空间,也可以减少镜像文件下载占用的网络资源。
作为容器文件系统,UnionFS 通过多个目录挂载的方式工作。OverlayFS 就是 UnionFS 的一种实现,是目前主流 Linux 发行版本中缺省使用的容器文件系统。
OverlayFS 也是把多个目录合并挂载,被挂载的目录分为两大类:lowerdir 和 upperdir。
lowerdir 允许有多个目录,在被挂载后,这些目录里的文件都是不会被修改或者删除的,也就是只读的;upperdir 只有一个,不过这个目录是可读写的,挂载点目录中的所有文件修改都会在 upperdir 中反映出来
容器写文件的延时为什么波动很大?
根据 ftrace 的结果,我们发现写数据到 Page Cache 的时候,需要不断地去释放原有的页面,这个时间开销是最大的。造成容器中 Buffered I/O write() 不稳定的原因,正是容器在限制内存之后,Page Cache 的数量较小并且不断申请释放
其实这个问题也提醒了我们:
在对容器做 Memory Cgroup 限制内存大小的时候,不仅要考虑容器中进程实际使用的内存量,还要考虑容器中程序 I/O 的量,合理预留足够的内存作为Buffered I/O 的 Page Cache
容器网络
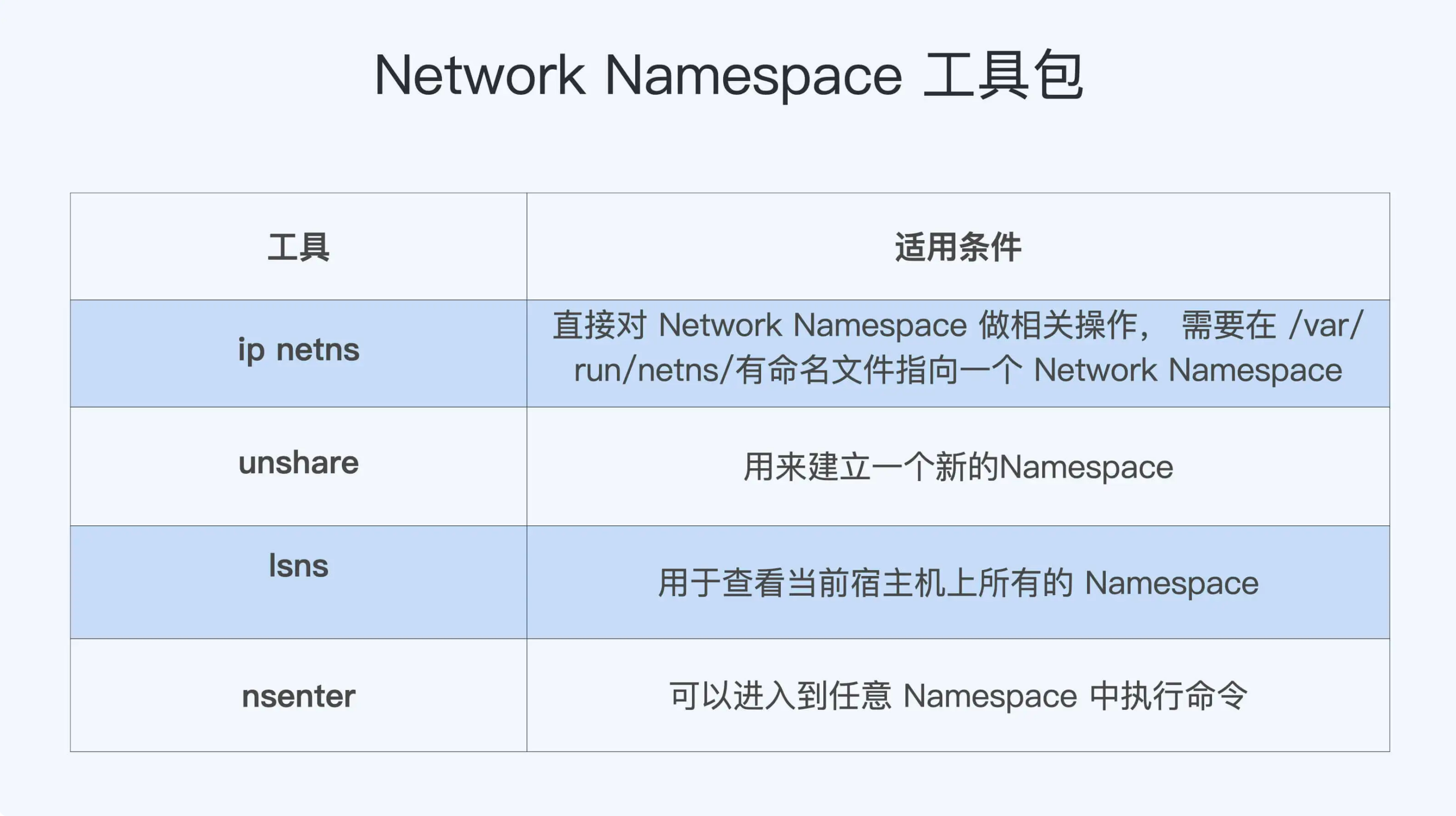
Network Namespace 可以隔离网络设备,ip 协议栈,ip 路由表,防火墙规则,以及可以显示独立的网络状态信息。
我们可以通过 clone() 或者 unshare() 系统调用来建立新的 Network Namespace。
由于安全的原因,普通容器的 /proc/sys 是 read-only mount 的,所以在容器启动以后,我们无法在容器内部修改 /proc/sys/net 下网络相关的参数。
这时可行的方法是通过 runC sysctl 相关的接口,在容器启动的时候对容器内的网络参数做配置。
这样一来,想要修改网络参数就可以这么做:如果是使用 Docker,我们可以加上"—sysctl"这个参数;而如果使用 Kubernetes 的话,就需要用到"allowed unsaft sysctl"这个特性了
veth模式
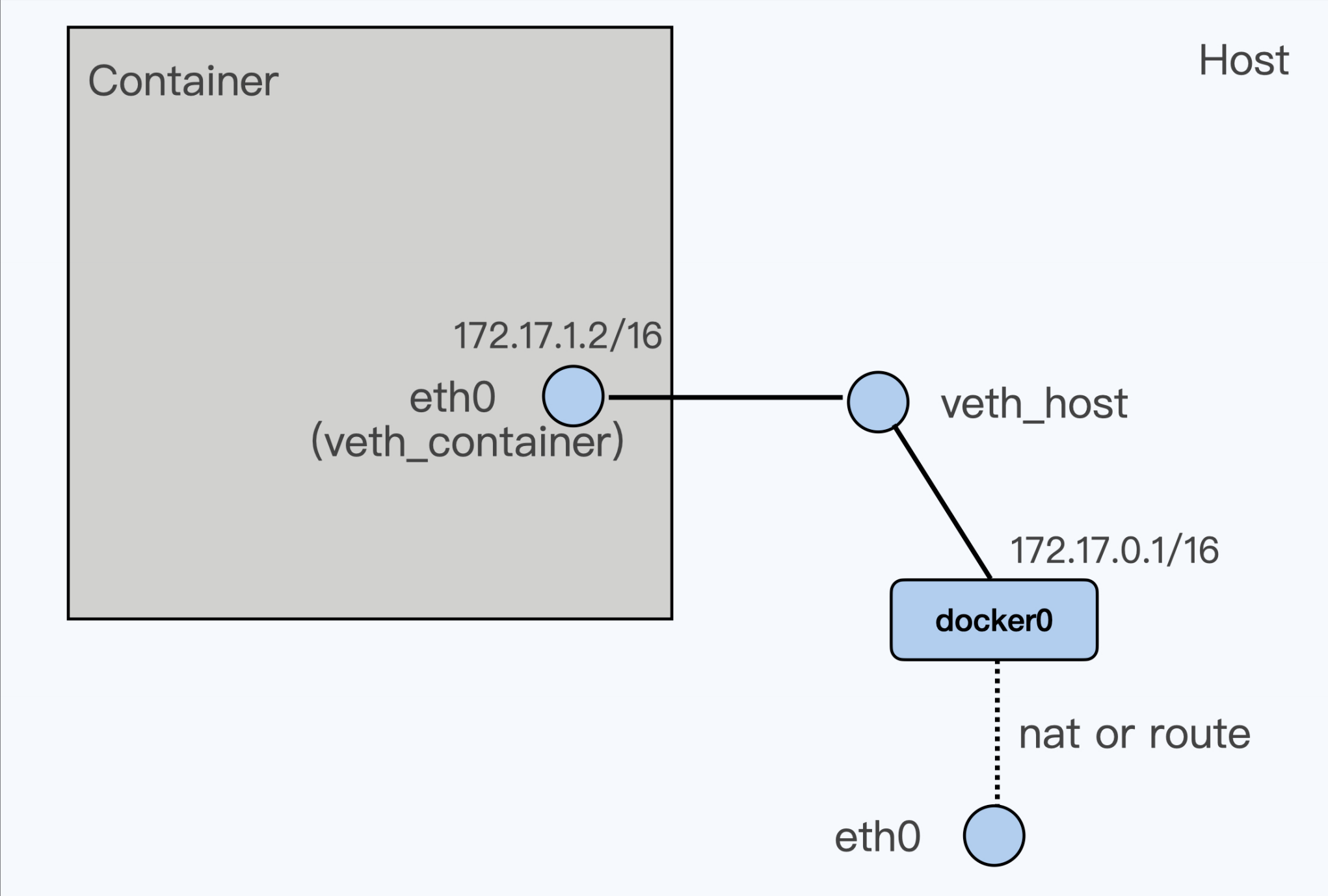
根据 veth 这个虚拟网络设备的实现方式,我们可以看到它必然会带来额外的开销,这样就会增加数据包的网络延时
macvlan/ipvlan模式
对于 macvlan,每个虚拟网络接口都有自己独立的 mac 地址,而 ipvlan 的虚拟网络接口是和物理网络接口共享同一个 mac 地址
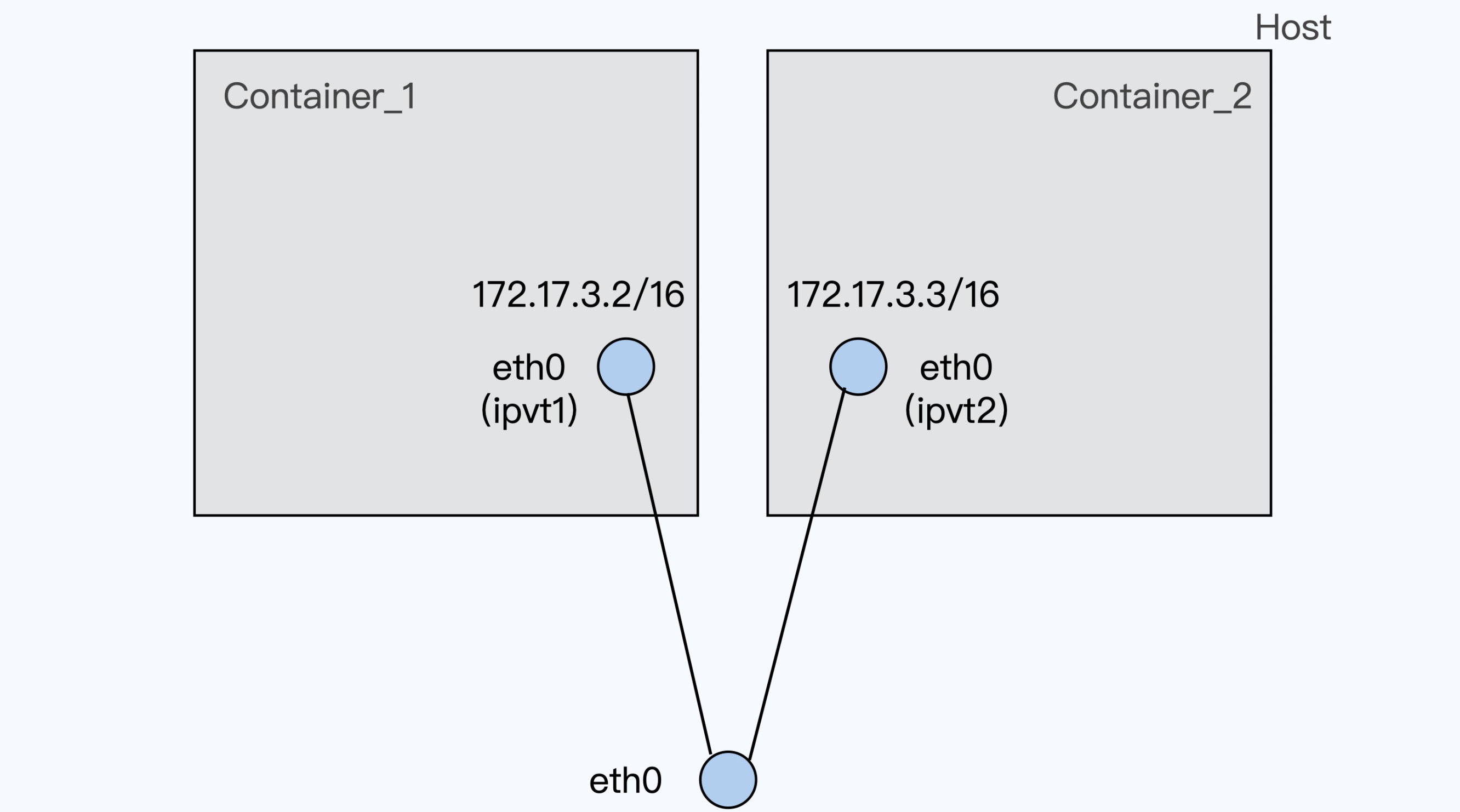
容器通常缺省使用 veth 虚拟网络接口,不过 veth 接口会有比较大的网络延时。我们可以使用 netperf 这个工具来比较网络延时,相比物理机上的网络延时,使用 veth 接口容器的网络延时会增加超过 10%
如果要减小容器网络延时,就可以给容器配置 ipvlan/macvlan 的网络接口来替代 veth 网络
接口。Ipvlan/macvlan 直接在物理网络接口上虚拟出接口,在发送对外数据包的时候可以直接通过物理接口完成,没有节点内部类似 veth 的那种 softirq 的开销。容器使用ipvlan/maclan 的网络接口,它的网络延时可以非常接近物理网络接口的延时**
对于延时敏感的应用程序,我们可以考虑使用 ipvlan/macvlan 网络接口的容器。不过,由于ipvlan/macvlan 网络接口直接挂载在物理网络接口上,对于需要使用 iptables 规则的容器,比如 Kubernetes 里使用 service 的容器,就不能工作了。这就需要你结合实际应用的需求做个判断,再选择合适的方案。
容器中的网络乱序包
我们再对容器云平台中的快速重传做分析,就会发现这些重传大部分是由包的乱序触发的。通过对容器 veth 网络接口进一步研究,我们知道它可能会增加数据包乱序的几率。同时在这个分析过程中,我们也看到了 Linux 网络 RPS 的特性。
RPS 和 RSS 的作用类似,都是把数据包分散到更多的 CPU 上进行处理,使得系统有更强的网络包处理能力。它们的区别是 RSS 工作在网卡的硬件层,而 RPS 工作在 Linux 内核的软件层。
在把数据包分散到各个 CPU 时,RPS 保证了同一个数据流是在一个 CPU 上的,这样就可以有效减少包的乱序。那么我们可以把 RPS 的这个特性配置到 veth 网络接口上,来减少数据包乱序的几率。
不过,我这里还要说明的是,RPS 的配置还是会带来额外的系统开销,在某些网络环境中会引起 softirq CPU 使用率的增大。那接口要不要打开 RPS 呢?这个问题你需要根据实际情况来做个权衡。
同时你还要注意,TCP 的乱序包,并不一定都会产生数据包的重传。想要减少网络数据包的重传,我们还可以考虑协议栈中其他参数的设置,比如 /proc/sys/net/ipv4/tcp_reordering
容器安全
特权容器
我们需要先来理解什么是 Linux capabilities。其实 Linux capabilities 就是把Linux root 用户原来所有的特权做了细化,可以更加细粒度地给进程赋予不同权限
对于容器的 root 用户,缺省只赋予了 15 个 capabilities。如果我们发现容器中进程的权限不够,就需要分析它需要的最小 capabilities 集合,而不是直接赋予容器"privileged"。
因为"privileged"包含了所有的 Linux capabilities, 这样"privileged"就可以轻易获取宿主机上的所有资源,这会对宿主机的安全产生威胁。所以,我们要根据容器中进程需要的最少特权来赋予 capabilities。
尽管容器中 root 用户的 Linux capabilities 已经减少了很多,但是在没有 User Namespace的情况下,容器中 root 用户和宿主机上的 root 用户的 uid 是完全相同的,一旦有软件的漏洞,容器中的 root 用户就可以操控整个宿主机。
**为了减少安全风险,业界都是建议在容器中以非 root 用户来运行进程。**不过在没有 UserNamespace 的情况下,在容器中使用非 root 用户,对于容器云平台来说,对 uid 的管理会比较麻烦。
所以,我们还是要分析一下 User Namespace,它带来的好处有两个。一个是把容器中 root用户(uid 0)映射成宿主机上的普通用户,另外一个好处是在云平台里对于容器 uid 的分配要容易些。
除了在容器中以非 root 用户来运行进程外,Docker 和 podman 都支持了 rootlesscontainer,也就是说它们都可以以非 root 用户来启动和管理容器,这样就进一步降低了容器的安全风险
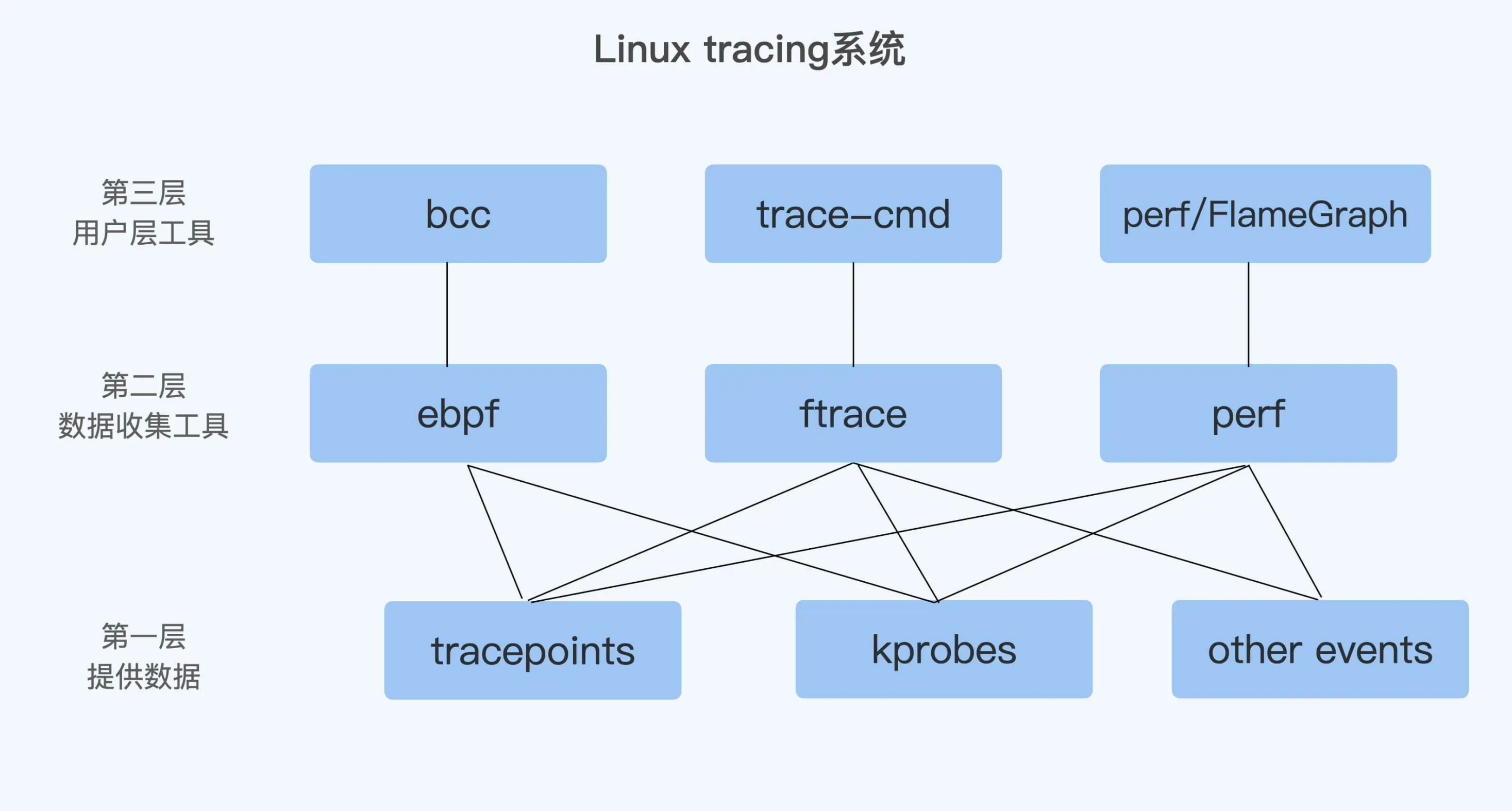
Linux tracing系统
参考资料